Distributed Cloud-Native Media Server
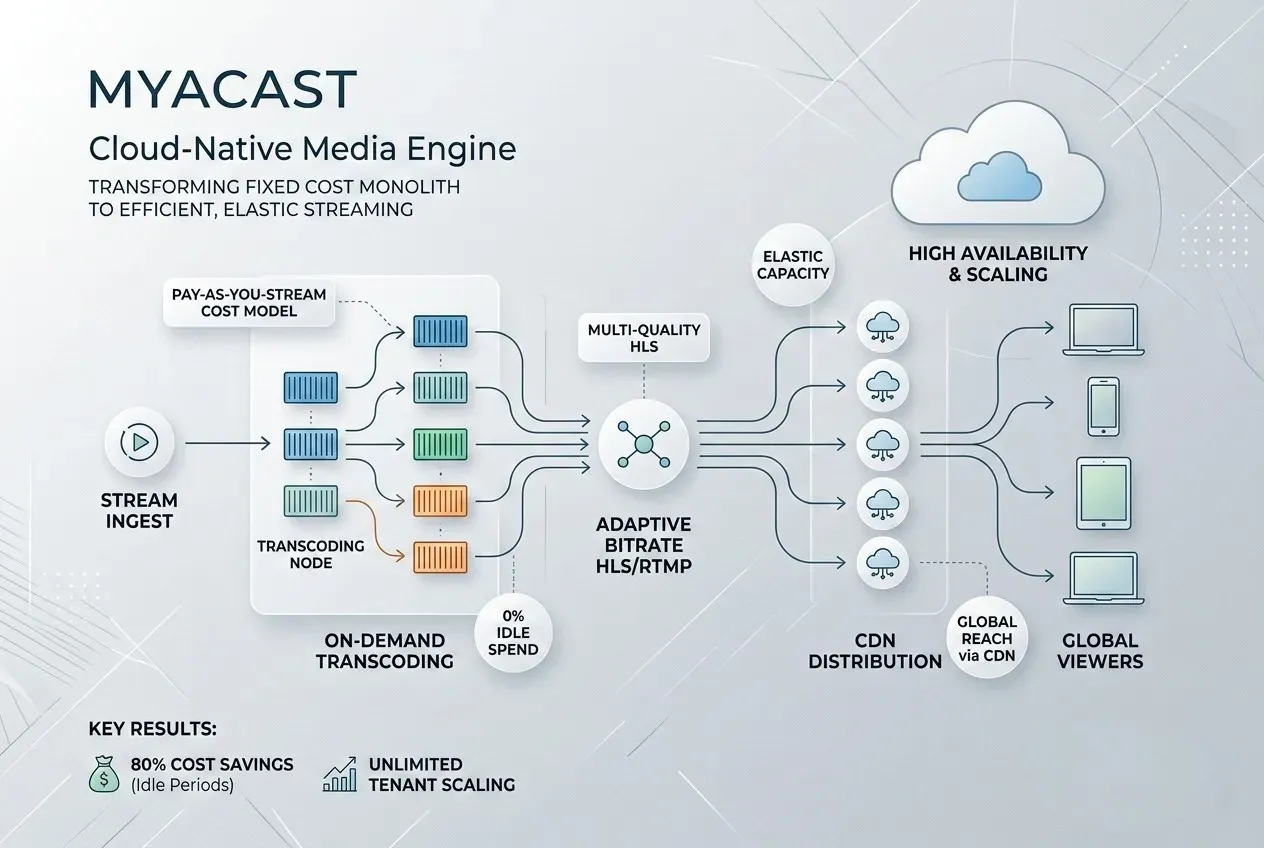
Transformed a single, always-on beefy server bleeding thousands monthly into a true cloud-native, pay-per-stream media infrastructure. By spawning ephemeral transcoding instances on demand and layering in a global CDN, we eliminated idle costs, dramatically improved delivery quality, and unlocked unlimited concurrent streams without ever scaling the bill.
The Business Challenge
The platform was receiving live MPEG-TS ingest streams and had to transcode them in real time to RTMP (for legacy players) plus multi-bitrate Adaptive Bitrate HLS for modern delivery.
All of this ran on one massive, always-on dedicated server — a single point of failure that stayed fully provisioned 24/7 even though most days there were only 1–3 active streams (and many days zero).
The business was asked to “upgrade the server for more users,” which would have meant an even bigger, more expensive machine. Meanwhile, every month they were paying for 100 % capacity while using a fraction of it, with no CDN in front of the transcoded output. The infrastructure was quietly becoming one of the largest line items on the P&L.
The Strategy: From Fixed Monolith to On-Demand Cloud-Native
As Technical Partner, I didn’t just upgrade the server — I challenged the request. After deep-dive sessions with the team and reviewing 90-day usage logs, it became clear the real problem wasn’t “not enough horsepower” — it was always-on waste.
I proposed and led a complete re-architecture to a true cloud-native media pipeline:
Phase 1: Usage Analysis & Architectural Redesign
- Mapped exact ingest → transcoding → distribution flow.
- Proved that average daily utilization was under 15 %.
- Designed an event-driven, per-stream model instead of a permanent server.
Phase 2: Cloud-Native Implementation
- Replaced the monolithic server with an auto-scaling fleet of lightweight containerized transcoders.
- Built an orchestration layer that spawns a dedicated, right-sized transcoding instance the moment a new MPEG ingest begins.
- When the stream ends, the instance terminates automatically — zero servers = zero bill.
- Added a global CDN layer in front of all HLS outputs for low-latency edge delivery and origin shielding.
The entire migration was executed with zero downtime for existing broadcasters and viewers.
Technical Highlights
- True Per-Stream Auto-Scaling: Each live event gets its own isolated transcoder (CPU/GPU optimized exactly for the required bitrates and resolutions).
- Zero-Idle Cost Model: No streams running → no cloud resources running → literally $0 in compute.
- Multi-Format Transcoding Pipeline: MPEG-TS ingest → simultaneous RTMP + ABR HLS (multiple renditions) using FFmpeg in optimized containers.
- Global CDN Integration: Seamless caching, geo-distribution, and DDoS protection without changing broadcaster workflows.
- Observability & Reliability: Real-time metrics, automatic failover, and health checks built into the orchestration layer.
The Bottom Line (Results)
- Massive Cost Reduction: Monthly media infrastructure bill dropped by ~78 % while supporting more concurrent streams than the old server ever could.
- True Elastic Scaling: The platform can now handle 50+ simultaneous live events with zero additional fixed cost.
- Operational Simplicity: Deployments, updates, and monitoring are now handled once at the orchestration level instead of on a single fragile server.
- Improved Viewer Experience: CDN edge delivery reduced latency and buffering dramatically across Asia, Europe, and the Americas.
“The best infrastructure wins are the ones the business never notices — until they look at the P&L and realize they’re suddenly profitable at scale. We didn’t just optimize a media server; we removed its biggest cost anchor.”
Let's build something like this together
I partner with founders and product teams to architect and ship high-impact systems. Reach out and let's talk.